Week 6
Thinking in C++, vol. 1, Chapter 5
OO concepts: encapsulation, implementation hiding
Exercises in the usual repository, week6 subdirectory
Access control
Public, protected, and private class data members and methods
- public
The most open level of data hiding is public. Anything that is public is available to all derived classes of a base class, and the public variables and data for each object of both the base and derived class is accessible by code outside the class. Everything following is public until the end of the class or another data hiding keyword is used.
In general, a well-designed class will have no public fields--everything should go through the class's functions.
- protected
Variables and functions marked protected are inherited by derived classes; however, these derived classes hide the data from code outside of any instance of the object. Keep in mind, even if you have another object of the same type as your first object, the second object cannot access a protected variable in the first object. Instead, the second object will have its own variable with the same name, but not necessarily the same data.
- private
Functions and variables marked private are not accessible by code outside the specific object in which that data appears. Private variables and functions are not inherited by derived classes.
Public, protected, and private inheritance
- class A
- {
- public:
- int x;
- protected:
- int y;
- private:
- int z;
- };
1. Public inheritance: Is-a relationship Everywhere where A is needed, B can be passed.
- class B : public A
- {
- // x is public
- // y is protected
- // z is not accessible from B
- };
2. Protected inheritance: implemented-in-terms-of relationship. Rarely useful.
- class C : protected A
- {
- // x is protected
- // y is protected
- // z is not accessible from C
- };
3. Private inheritance: implemented-in-terms-of relationship. Useful for traits (which we haven't covered yet).
- class D : private A
- {
- // x is private
- // y is private
- // z is not accessible from D
- };
Only members/friends of a class can see private inheritance, and only members/friends and derived classes can see protected inheritance.
Note that C-style casts allow casting a derived class to a protected or private base class in a defined and safe manner, as well as casting a base class to a derived class. This should be avoided at all costs, because it can make code dependent on implementation details. This can be prevented by using class handles as explained a bit later.
Friends
A class can allow another class to access its protected and private members by declaring it as a friend class or struct.
Example: Suppose we have a class Farmer that needs to access a Sheep's wool, but the Sheep's wool is a private data member. We could add the Farmer class as a friend of Sheep.
More Friend examples.
Class handles -- really hiding a class
Suppose your Cheshire class declaration must remain as private as possible, i.e., only the public members should be visible to anyone. Normally you would have a cheshire.hpp header file defining the Cheshire class, but then you will expose the types and names of protected and private variables and methods and they may reveal implementation details and may be accessed maliciously.
- #ifndef CHESHIREHANDLE_H
- #define CHESHIREHANDLE_H
- class CheshireHandle {
- struct Cheshire; // Class declaration only
- Cheshire* smile;
- public:
- void initialize();
- void cleanup();
- int read();
- void change(int);
- };
- #endif // CHESHIREHANDLE_H
Constructors
A constructor is a member function with the same name as its class (see TICPPv1 Chapter 6). For example:
- class X {
- public:
- X(); // constructor for class X
- };
Constructors are used to create, and can initialize, objects of their class type.
You cannot declare a constructor as virtual or static, nor can you declare a constructor as const, volatile, or const volatile.
You do not specify a return type for a constructor. A return statement in the body of a constructor cannot have a return value.
A bit more on the "volatile" and "const volatile" type qualifiers.
- volatile tells the compiler not to optimize any code related the variable, usually, when we know it can be changed from "outside", e.g. by another thread or system calls.
- const will tell the compiler that it is forbidden for the program to modify the variable's value.
- const volatile is a very special and rare case. It means that the program cannot modify the variable's value (const), but the value can be modified from the outside (volatile), thus no optimizations will be performed on the variable.
Delegating constructors
In C++ 11 you can delegate object construction to the parent class, for example:
- class Foo
- {
- public:
- Foo()
- {
- // code to do A
- }
- Foo(int nValue): Foo() // use Foo() default constructor to do A
- {
- // code to do B
- }
- };
Note that you cannot do both constructor delegation and an initializer list for initializing data members.
Default constructors
A default constructor is a constructor that either has no parameters, or if it has parameters, all the parameters have default values.
If no user-defined constructor exists for a class A and one is needed, the compiler implicitly declares a default parameterless constructor A::A(). This constructor is an inline public member of its class. The compiler will implicitly define A::A() when the compiler uses this constructor to create an object of type A.
The compiler first implicitly defines the implicitly declared constructors of the base classes and nonstatic data members of a class A before defining the implicitly declared constructor of A.
A constructor of a class A is trivial if all the following are true:
- It is implicitly defined
- A has no virtual functions and no virtual base classes
- All the direct base classes of A have trivial constructors
- The classes of all the nonstatic data members of A have trivial constructors
If any of the above are false, then the constructor is nontrivial.
Destructors
Destructors are usually used to deallocate memory and do other cleanup for a class object and its class members when the object is destroyed. A destructor is called for a class object when that object passes out of scope or is explicitly deleted.
A destructor is a member function with the same name as its class prefixed by a ~ (tilde). For example:
- class X {
- public:
- // Constructor for class X
- X();
- // Destructor for class X
- ~X();
- };
A destructor takes no arguments and has no return type. Its address cannot be taken. Destructors cannot be declared const, volatile, const volatile or static. A destructor can be declared virtual or pure virtual.
If no user-defined destructor exists for a class and one is needed, the compiler implicitly declares a destructor. This implicitly-declared destructor is an inline public member of its class.
The compiler will implicitly define an implicitly declared destructor when the compiler uses the destructor to destroy an object of the destructor's class type. Suppose a class A has an implicitly declared destructor. The following is equivalent to the function the compiler would implicitly define for A:
A::~A() { }
The compiler first implicitly defines the implicitly declared destructors of the base classes and nonstatic data members of a class A before defining the implicitly declared destructor of A
A destructor of a class A is trivial if all the following are true:
- It is implicitly defined
- All the direct base classes of A have trivial destructors
- The classes of all the nonstatic data members of A have trivial destructors
- If any of the above are false, then the destructor is nontrivial.
A union member cannot be of a class type that has a nontrivial destructor.
Class members that are class types can have their own destructors. Both base and derived classes can have destructors, although destructors are not inherited. If a base class A or a member of A has a destructor, and a class derived from A does not declare a destructor, a default destructor is generated.
The default destructor calls the destructors of the base class and members of the derived class.
The destructors of base classes and members are called in the reverse order of the completion of their constructor:
- The destructor for a class object is called before destructors for members and bases are called.
- Destructors for nonstatic members are called before destructors for base classes are called.
- Destructors for nonvirtual base classes are called before destructors for virtual base classes are called.
Constructor initializer lists
The rule of three
Next we will discuss function overloading, with a focus on constructors, and in particular, introducing the copy constructor and the move constructor.
Function overloading
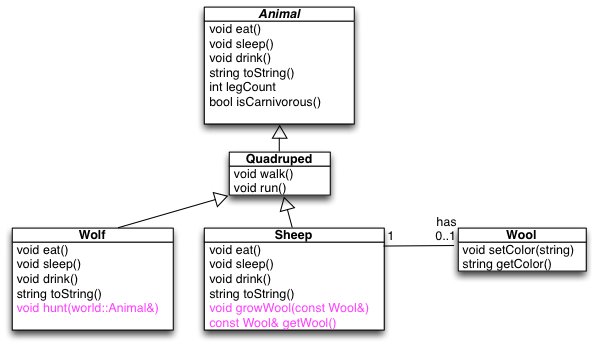
In our lecture exercises (week6 subdirectory), we overload several methods in the Sheep and Wolf classes.
In the current assignment, we overload the encrypt and decrypt methods to define different encryption schemes.
Next we take a look at overloading functions based on whether the argument is an lvalue or an rvalue. This is a lot less obvious than examples that simply take different numbers or types of arguments because it requires some understanding of how the compiler represents objects.
Copy and move constructors
We have seen simple constructors in many of the classes in assignments and lectures. Two other types of constructors that are commonly defined by classes are the copy and move constructors.
Suppose you have a class encapsulating a 2-D array, e.g., representing a Checkers board.
- class Checkers {
- public:
- Checkers(int size_p) : size(size_p) { /* allocate the 2D board array here */ };
- ~Checkers() { /* free the 2D board array here */ }
- // ... more methods ..
- private:
- int size;
- char **board;
- };
A copy constructor allows you to create a new object by copying from an existing one. For example, suppose you want to create a new Checkers instance from an existing one (which you will no longer need), you would define that as
- Checkers(const Checkers& rhs) : size(rhs.size) { // .. more initializations ...}
- //...
- // then in your main:
- Checkers oldCheckers(5); // Creates a 5x5 board
- Checkers newCheckers(oldCheckers) // Creates another instance, but same board!
(assuming that the checkers board is defined as a 2-D char array private data member of Checkers. Note that this is what is called a shallow copy, in that it only copies the pointer to the actual board. A deep copy would loop over rhs.board and assign it to this->board element by element.)
Even though you may know that you'll never need oldCheckers again, the compiler will keep two objects allocated, oldCheckers and newCheckers -- there is no way to indicate that oldCheckers can be discarded after the newCheckers is constructed or to avoid having two objects in memory at the same time.
So how do we get rid of such "temporary" objects? One solution is to use move semantics. In the case of object construction, this means implementing a move constructor.
lvalues and rvalues
To understand the difference between copy and move constructors, we first need to introduce the concepts of lvalues and rvalues. You can find detailed descriptions of value categories in C++ here.
An lvalue is an expression that refers to a memory location and allows us to take the address of that memory location via the & operator. You can also think of lvalue as something that can be the left-hand side of an assignment statement. An rvalue is an expression that is not an lvalue. Examples are:
- // lvalues:
- //
- int i = 42;
- i = 43; // ok, i is an lvalue
- int* p = &i; // ok, i is an lvalue
- int& foo();
- foo() = 42; // ok, foo() is an lvalue
- int* p1 = &foo(); // ok, foo() is an lvalue
- // rvalues:
- //
- int foobar();
- int j = 0;
- j = foobar(); // ok, foobar() is an rvalue
- int* p2 = &foobar(); // error, cannot take the address of an rvalue
- j = 42; // ok, 42 is an rvalue
Move semantics
A move constructor of class T is a non-template constructor whose first parameter is T&&, const T&&, volatile T&&, or const volatile T&&, and either there are no other parameters, or the rest of the parameters all have default values.
In the week6/move-constructor/sheep.hpp implementation:
- class Wool {
- public:
- // Constructors
- // Default constructor
- Wool() : color("White") {}
- // Constructor with initialization
- Wool(string c) : color(c) {}
- // Copy constructor:
- Wool(const Wool& other) : color(other.color) {}
- // Move constructor
- Wool(Wool&& other) : color(other.color) {}
- inline void setColor(string color);
- inline const string getColor();
- private:
- string color;
- };
So what is the difference between the copy constructor and the move constructor? The main distinction is that when using a move constructor, the compiler will not create temporary copies of values or variables on the stack, which reduces memory use (fewer mallocs!) and improves performance.
Rvalue References in more detail
If X is any type, then X&& is called an rvalue reference to X. For better distinction, the ordinary reference X& is now also called an lvalue reference.
An rvalue reference is a type that behaves much like the ordinary reference X&, with several exceptions. The most important one is that when it comes to function overload resolution, lvalues "prefer" old-style lvalue references, whereas rvalues "prefer" the new rvalue references:
- void foo(X& x); // lvalue reference overload
- void foo(X&& x); // rvalue reference overload
- X x;
- X foobar();
- foo(x); // argument is lvalue: calls foo(X&)
- foo(foobar()); // argument is rvalue: calls foo(X&&)
It is true that you can overload any function in this manner, as shown above. But in the overwhelming majority of cases, this kind of overload should occur only for copy constructors and assignment operators, for the purpose of achieving move semantics.
For an example illustrating the performance advantages of move constructors, see this blog article.
For a quick and clear introduction, you can also watch https://youtu.be/PNRju6_yn3o?t=68 (up to minute 9).
<<End of move semantics discussion>>
Overloading based on return value only
C++ does not allow definition of two functions that differ only in return values, for example, the following will produce an error:
int sum(); double sum();
However, templates offer a mechanism to do just that. More on this later...
template <class T>
T sum() {
T result;
// code to compute result
return result;
}