Week 5 (cont.)
Smart pointers
Smart pointers are a very helpful tool to avoid manual memory management and all the issues connected with it (memory leaks, unclear ownership semantics, double deletions, exception safety, ...). Basically, smart pointers are class templates that encapsulate a raw pointer and free memory in the destructor. This makes RAII possible, a fundamental idiom for resource management in modern C++.
RAII stands for Resource Acquisition Is Initialization and is a method for handling resources, such as memory, fonts, files etc. to ensure that they are released when no longer needed or when a process terminates due to an error. Resources are generally tied to objects. A file handling class will probably require a file handle to access a file, for opening, reading or writing the file. Once the object is finished with the file, the resource must be released.
The original (now deprecated smart pointer): auto_ptr -- read only as a motivational reference explaining the need for smart pointers, but keep in mind that auto_ptr has been replaced by shared_ptr, weak_ptr, and unique_ptr in C++11. If you are curious why auto_ptr was deprecated, read this.
shared_ptr and weak_ptr
The next two pointers, shared_ptr and weak_ptr try to relieve some of the headaches of resource allocation and release when using auto_ptr.
They can do much more than help you release dynamically allocated memory! They can help release any kind of resource whether it be memory, file handles or semaphores.
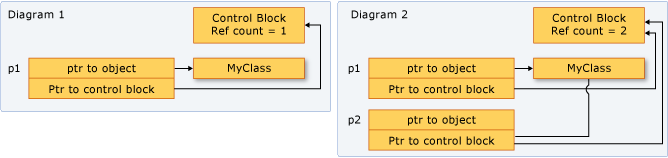
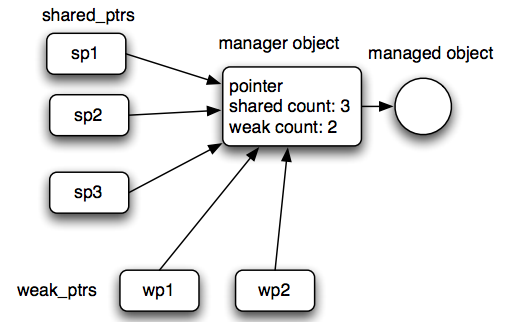
The implementation of these smart pointers is rather complex, but the semantics is quite simple. For example, if you have three shared pointers and two weak pointers pointing to the same object, you can conceptually visualize the situation like this:
The Headers
The header you need to include in order to use smart pointers is:
#include <memory>
For a preliminary example let's assume we are holding a dynamically allocated int, this is how we would declare that:
std::shared_ptr<int> sp;
To declare a shared_ptr to any dynamically allocated object:
std::shared_ptr<MyClass> sp;
Simple example:
- // File: shared_ptr1.cpp
- #include <iostream>
- #include <memory>
- using namespace std;
- class MyClass {
- public:
- MyClass(){
- cout << "Creating MyClass object" << endl;
- }
- virtual ~MyClass(){
- cout << "Destroying MyClass object" << endl;
- }
- void method(){
- cout << "Called method of MyClass object" << endl;
- }
- };
- shared_ptr<MyClass> returnTest() {
- shared_ptr<MyClass> m(new MyClass);
- m->method();
- return m;
- }
- int main() {
- shared_ptr<MyClass> m2 = returnTest();
- m2->method();
- return 0;
- }
This produces the following output:
Creating MyClass object Called method of MyClass object Called method of MyClass object Destroying MyClass object
It is also possible to track how many shared_ptr objects are holding onto a pointer through the use of the use_count function:
- // File: shared_ptr2.cpp
- #include <iostream>
- #include <memory>
- using namespace std;
- class A {
- public:
- void f() {}
- };
- int main() {
- shared_ptr<A> pA1(new A());
- pA1->f();
- if (pA1) {}
- A& a = *pA1;
- cout << "pA1 use_count = " << pA1.use_count() << endl;
- shared_ptr<A> pA2(pA1);
- cout << endl << "After creating pA2:" << endl;
- cout << "pA1 use_count = " << pA1.use_count() << endl;
- cout << "pA2 use_count = " << pA2.use_count() << endl;
- pA1.reset();
- cout << endl << "After reset:" << endl;
- cout << "pA1 use_count = " << pA1.use_count() << endl;
- cout << "pA2 use_count = " << pA2.use_count() << endl;
- }
This example declares a simple class A with a single member function. You can instantiate a shared_ptr by using either a raw pointer to A (as in the case of pA1 in the code above) or through another shared_ptr variable (as in the case of pA2). Operator overloads exist for conversion to Boolean along with the operators -> and &, which allow you to use natural, pointer-like syntax with shared_ptr. When you run the preceding example, the output is:
pA1 use_count = 1 After creating pA2: pA1 use_count = 2 pA2 use_count = 2 After reset: pA1 use_count = 0 pA2 use_count = 1
When the code declares the first shared pointer (pA1) and initializes it to the heap-allocated A object, it has a use_count of one. When it creates pA2, which points to the same underlying heap object, the use_count gets bumped up to two, as shown in the output. Finally, calling the reset method on pA1 releases its association with the underlying heap object, giving it a use_count of zero, while the use_count for pA2 drops to one.
The shared_ptr class can also track a chain of links between instances that point to the same underlying heap object, so if you use pA1 to create a new shared_ptr (pA3), the usage count of all three shared_ptr objects (including pA2, which wasn't involved in the assignment to pA3) will be incremented:
- shared_ptr<A> pA1(new A());
- shared_ptr<A> pA2(pA1);
- cout << endl << "After creating pA2" << endl;
- cout << "pA1 use_count = " << pA1.use_count() << endl;
- cout << "pA2 use_count = " << pA2.use_count() << endl;
- shared_ptr<A> pA3(pA1);
- cout << endl << "After creating pA3" << endl;
- cout << "pA1 use_count = " << pA1.use_count() << endl;
- cout << "pA2 use_count = " << pA2.use_count() << endl;
- cout << "pA3 use_count = " << pA3.use_count() << endl;
After creating pA2: pA1 use_count = 2 pA2 use_count = 2 After creating pA3: pA1 use_count = 3 pA2 use_count = 3 pA3 use_count = 3
However, if you retrieve the raw pointer and use that to create a new shared_ptr object, the usage count for the original chain of shared_ptr objects will not get incremented, and you're likely to get an application error caused by resources being freed too early. The following code sample shows two incorrect uses of shared_ptr objects:
- cout << endl << "pA2 use_count before pA4 = " << pA2.use_count() << endl;
- shared_ptr<A> pA4(pA1.get());
- cout << "pA2 use_count after pA4 = " << pA2.use_count() << endl;
- size_t pA5 = (size_t)pA3.get();
- shared_ptr<A> pA6((A*)pA5);
- cout << "pA2 use_count after pA5 = " << pA2.use_count() << endl;
Result:
pA2 use_count before pA4 = 3 pA2 use_count after pA4 = 3 pA2 use_count after pA6 = 3
The classic problem associated with reference counting schemes is circular references, where strong_ptr A points to B, which points to C, which in turn points back to A. As the reference count is not decremented when one of the objects goes out of scope, the resources held by the pointers are not freed. The weak_ptr class, which ships in the same header file as shared_ptr, solves this issue by allowing a pointer to be held without the risk of a circular reference preventing resource cleanup. The weak_ptr class is useful in cases where a referenced object wants to hold a back-pointer to its parent, and the lifetimes of the parent and child are tightly coupled. With tight coupling, the back pointer does not need to hold a strong reference to the parent to keep it alive, and doing so would be dangerous from a circular-reference viewpoint.
This code sample shows the parent-child relationship with the use of weak_ptr. Note that while it passes a shared_ptr into the child's constructor, it is actually used to create a weak_ptr; the shared_ptr will go out of scope after the constructor completes.
- class Child {
- private:
- weak_ptr<Parent> pParent;
- public:
- Child(shared_ptr<Parent> parent): pParent(parent){}
- };
- class Parent {
- private:
- shared_ptr<Child> pChild;
- public:
- Parent()
- {
- pChild = shared_ptr<Child>(new Child(shared_ptr<Parent>(this)));
- }
- };
Perfect forwarding
Reference: this subsection is based on A Brief Introduction to Rvalue References by Howard E. Hinnant, Bjarne Stroustrup, and Bronek Kozicki.
Consider writing a generic factory function that returns a std::shared_ptr for a newly constructed generic type. Factory functions such as this are valuable for encapsulating and localizing the allocation of resources. Obviously, the factory function must accept exactly the same sets of arguments as the constructors of the type of objects constructed. Today this might be coded as:
- template <class T>
- std::shared_ptr<T>
- factory() // no argument version
- {
- return std::shared_ptr<T>(new T);
- }
- template <class T, class A1>
- std::shared_ptr<T>
- factory(const A1& a1) // one argument version
- {
- return std::shared_ptr<T>(new T(a1));
- }
- // ... all the other versions
In the interest of brevity, we will focus on just the one-parameter version. For example:
std::shared_ptr<A> p = factory<A>(5);
Question: What if T's constructor takes a parameter by non-const reference?
In that case, we get a compile-time error as the const-qualifed argument of the factory function will not bind to the non-const parameter of T's constructor.
To solve that problem, we could use non-const parameters in our factory functions:
- template <class T, class A1>
- std::shared_ptr<T>
- factory(A1& a1)
- {
- return std::shared_ptr<T>(new T(a1));
- }
This is much better. If a const-qualified type is passed to the factory, the const will be deduced into the template parameter (A1 for example) and then properly forwarded to T's constructor. Similarly, if a non-const argument is given to factory, it will be correctly forwarded to T's constructor as a non-const. Indeed, this is precisely how forwarding applications are coded today (e.g. std::bind).
However, consider:
- std::shared_ptr<A> p = factory<A>(5); // error
- A* q = new A(5); // ok
This example worked with our first version of factory, but now it's broken: The "5" causes the factory template argument to be deduced as int& and subsequently will not bind to the rvalue "5". Neither solution so far is right. Each breaks reasonable and common code.
Question: What about overloading on every combination of AI& and const AI&?
This would allow us to handle all examples, but at a cost of an exponential explosion: For our two-parameter case, this would require 4 overloads. For a three-parameter factory we would need 8 additional overloads. For a four-parameter factory we would need 16, and so on. This is not a scalable solution.
Rvalue references offer a simple, scalable solution to this problem:
- template <class T, class A1>
- std::shared_ptr<T>
- factory(A1&& a1)
- {
- return std::shared_ptr<T>(new T(std::forward<A1>(a1)));
- }
Now rvalue arguments can bind to the factory parameters. If the argument is const, that fact gets deduced into the factory template parameter type.
Question: What is that forward function in our solution?
Like move, forward is a simple standard library function used to express our intent directly and explicitly, rather than through potentially cryptic uses of references. We want to forward the argument a1, so we simply say so.
Here, forward preserves the lvalue/rvalue-ness of the argument that was passed to factory. If an rvalue is passed to factory, then an rvalue will be passed to T's constructor with the help of the forward function. Similarly, if an lvalue is passed to factory, it is forwarded to T's constructor as an lvalue.
The definition of forward looks like this:
- template <class T>
- struct identity
- {
- typedef T type;
- };
- template <class T>
- T&& forward(typename identity<T>::type&& a)
- {
- return a;
- }
unique_ptr
(This section is based on The Smart Pointer That Makes Your C++ Applications Safer - std::unique_ptr)
Using shared_ptr incurs noticeable performance overhead both in terms of size and speed. Hence, the C++ standard includes another smart pointer called unique_ptr that combines the best of both worlds -- it's very efficient (even more than auto_ptr was), and yet it's fully compatible with the Standard Library, as is shared_ptr. In addition, unique_ptr supports arrays, too.
What is the semantic difference between shared_ptr and unique_ptr? When using unique_ptr, there can be at most one unique_ptr pointing at any one resource. When that unique_ptr is destroyed, the resource is automatically reclaimed. Because there can only be one unique_ptr to any resource, any attempt to make a copy of a unique_ptr will cause a compile-time error.
Performance Issues
The first question you'd ask yourself is probably: "Why do I need to learn how to use another smart pointer class when shared_ptr fits the bill?" In one word: performance.
Shared_ptr uses reference counting to allow the sharing of a single resource by multiple objects. Additionally, its destructor and other member functions are virtual. These properties facilitate the customization of shared_ptr. However, the size of a typical shared_ptr object is 40 bytes, which is 10 times bigger than the size of a raw pointer on a 32-bit platform.
The presence of virtual member functions means that in many cases, calls to member functions are resolved dynamically, incurring additional runtime overhead. These issues may not concern you if you're using shared_ptr sporadically. However, in time critical apps, or if you have containers that store a large number of shared_ptr objects, the performance overhead might be overwhelming. Unique_ptr gives you a safe and reliable smart pointer alternative that can compete with the size and speed of raw pointers. Here's how it's used.
Using Unique_ptr
Important! std::unique_ptr is non-assignable and non-copyable. You need to use std::move(), e.g.,
- std::unique_ptr<int> p1(new int);
- std::unique_ptr<int> p2(new int);
- // p2=p1; // Wrong
- p1 = std::move(p2);
Even though unique_ptr is not a 100% source-compatible drop-in replacement for auto_ptr, everything you can do with auto_ptr, unique_ptr will do as well:
- #include <utility> //declarations of unique_ptr
- using std::unique_ptr;
- // default construction
- unique_ptr<int> up; //creates an empty object
- // initialize with an argument
- unique_ptr<int> uptr (new int(3));
- double *pd= new double;
- unique_ptr<double> uptr2 (pd);
- // overloaded * and ->
- *uptr2 = 23.5;
- unique_ptr<std::string> ups (new std::string("hello"));
- int len=ups->size();
reset() releases the owned resource and optionally acquires a new resource:
- unique_ptr<double> uptr2 (pd);
- uptr2.reset(new double); //delete pd and acquire a new pointer
- uptr2.reset(); //delete the pointer acquired by the previous reset() call
If you need to access the owned pointer directly use get():
- void func(double*);
- func(uptr.get());
Unique_ptr lets you install a custom deleter if necessary. A deleter is a callable entity (a function, function object etc.) that the smart pointer's destructor will invoke to deallocate its resource. Unique_ptr's default deleter calls delete. If the resource isn't an object allocated by new you'll need to install a different deleter. For instance, a pointer allocated by malloc() requires a deleter that calls free():
- #include <cstdlib>
- int* p=(int*)malloc(sizeof(int));
- unique_ptr<p, free> intptr; //initialized with a custom deleter
- *intptr=5;
swap() exchanges the resources and deleters of the two objects:
- unique_ptr<double, std::free> up1 ((double*)malloc(sizeof(double));
- unique_ptr<double> up2;
- up2.swap(up1);
- *up2=3.45;
Unique_ptr has implicit conversion to bool. This lets you use unique_ptr object in Boolean expressions such as this:
- if (up1) //implicit conversion to bool
- cout<<*up1<<endl;
- else
- cout<<"an empty smart pointer"<<endl;
Array Support
Unique_ptr can store arrays as well. A unique_ptr that owns an array defines an overloaded operator []. Obviously, the * and -> operators are not available. Additionally, the default deleter calls delete[] instead of delete:
- unique_ptr<int[]> arrup (new int[5]);
- arrup[0]=5;
- cout<<*arrup<<endl; //error, operator * not defined
- unique_ptr<char[], std::free> charup ((char*)( malloc(5));
- charup[1]='b';
Compatibility with Containers and Algorithms
You can safely store unique_ptr in Standard Library containers and let algorithms manipulate sequences of unique_ptr objects. For containers and algorithms that move elements around internally instead of copying them around, unique_ptr will work flawlessly. If however the container or algorithm uses copy semantics for its value_type you'll get a compilation error. Unlike with auto_ptr, there is no risk of a runtime crash due to a move operation disguised as copying:
- #include <vector>
- #include <memory> // unique_ptr
- #include <algorithm> // sort
- #include <iostream>
- using namespace std;
- struct indirect_less
- {
- template <class T>
- bool operator()(const T& x, const T& y)
- {return *x < *y;}
- };
- int main() {
- vector<unique_ptr<int> > vi;
- vi.push_back(unique_ptr<int>(new int(0))); // populate vector
- vi.push_back(unique_ptr<int>(new int(3)));
- vi.push_back(unique_ptr<int>(new int(2)));
- sort(vi.begin(), vi.end(), indirect_less()); //result: {0, 2, 3}
- for (auto it = vi.begin(); it != vi.end(); ++it)
- cout << **it << endl;
- }
As sort moves the unique_ptrs around, it will use swap (which does not require Copyability) or move construction / move assignment. Thus during the entire algorithm, the invariant that each item is owned and referenced by one and only one smart pointer is maintained. If the algorithm were to attempt a copy (e.g., by a programming mistake) a compile time error would result.
In conclusion, unique_ptr is the safe equivalent of the deprecated auto_ptr. Its small memory footprint and runtime efficiency make it a useful replacement for raw pointers. If you don't need to share resources, unique_ptr is the right choice for you.
Summary and best practices
Reference: http://herbsutter.com/elements-of-modern-c-style/
Always use the standard smart pointers, and non-owning raw pointers. Never use owning raw pointers and delete, except in rare cases when implementing your own low-level data structure (and even then keep that well encapsulated inside a class boundary).
If you know you�re the only owner of another object, use unique_ptr to express unique ownership. A �new T� expression should immediately initialize another object that owns it, typically a unique_ptr. A classic example is the Pimpl Idiom (see GotW #100):
- // C++11 Pimpl idiom: header file
- class widget {
- public:
- widget();
- // ... (see GotW #100) ...
- private:
- class impl;
- unique_ptr<impl> pimpl;
- };
- // implementation file
- class widget::impl { /*...*/ };
- widget::widget() : pimpl{ new impl{ /*...*/ } } { }
- // ...
Use shared_ptr to express shared ownership. Prefer to use make_shared to create shared objects efficiently.
- // C++98
- widget* pw = new widget();
- :::
- delete pw;
- // C++11
- auto pw = make_shared<widget>();
Use weak_ptr to break cycles and express optionality (e.g., implementing an object cache).
- // C++11
- class gadget;
- class widget {
- private:
- shared_ptr<gadget> g; // if shared ownership
- };
- class gadget {
- private:
- weak_ptr<widget> w;
- };
If you know another object is going to outlive you and you want to observe it, use a (non-owning) raw pointer.
- // C++11
- class node {
- vector<unique_ptr<node>> children;
- node* parent;
- public:
- :::
- };